RでGIS
先日、RでのGIS作業にむけた簡単なポスト(RでGIS:ベクター)を書いた(最近だと思っていたが実に二年以上たっている事実に驚愕)。今回はそのフォローアップとして、ラスターデータの取り扱いについても簡単に紹介してみたい。今回はsf、terra、exactextractr、tmapの4つを使うので、先にこれらを読み込んでおく。
pacman::p_load(sf,
terra,
exactextractr,
tmap,
tidyverse)terraによるラスター処理
Rによるラスターデータの解析は長らくrasterパッケージが使われてきたようだが(私も初期はこちらを利用)、最近ではterraが主流になっており、ほかのGIS系パッケージとも互換性が確保されてきた様子(いくつか対応していないものもあるようだが、細かく把握していない)。terraのほうが圧倒的に計算速度が速いので、こちらの例を挙げる。
データの読み込み
データの読み込みにはterra::rast()を使う。今回、ここで使うラスターファイルはCHELSAの気候データ(赤道付近で1km程度のメッシュ)。CHELSA_bio1_1981-2010_V.2.1.tif(1981-2010年の平均気温データ)のアメリカ、ノースカロライナ(NC)周辺を切り出し、.../static/gis/airtemp_nc.tifとして保存しておいた(Linkからダウンロード可能)。私はこのファイルパスを指定して読み込むが1、使用者は各自の保存先のパスを指定すれば読み込める。
# read data
# here::here() is a function that returns an absolute path
rs_air <- rast(here::here("static/gis/airtemp_nc.tif"))
print(rs_air)## class : SpatRaster
## dimensions : 325, 1064, 1 (nrow, ncol, nlyr)
## resolution : 0.008333333, 0.008333333 (x, y)
## extent : -84.32514, -75.45847, 33.88319, 36.59153 (xmin, xmax, ymin, ymax)
## coord. ref. : lon/lat WGS 84 (EPSG:4326)
## source : airtemp_nc.tif
## name : CHELSA_bio1_1981-2010_V.2.1
## min value : 5.15
## max value : 21.15読み込むと、データの概要がプリントされる。
| Name | Description |
|---|---|
class |
Rオブジェクトのクラス。 |
dimensions |
ラスターファイルの要素数を次元(行数、列数、値のレイヤー数)に分けて示したもの。今回の場合、325x1064セルのラスターで、気温データのみ。 |
resolution |
各セルのサイズ。小さいほど解像度が高い。単位はCRSに依拠。 |
extent |
ラスターの上下左右の端の値。 |
cood.ref. |
Coordinate Reference System (CRS)。今回はWGS 84。 |
source |
元データのファイル名。 |
name |
ラスターの名前。 |
min value |
ラスターの値の最小値。 |
max value |
ラスターの値の最大値。 |
このデータを視覚化する。tmap パッケージにある関数群が使える。
# visualize using `tmap` package
tm_shape(rs_air) +
tm_raster(title = "Temperature")## ## ── tmap v3 code detected ───────────────────────────────────────────────────────## [v3->v4] `tm_raster()`: migrate the argument(s) related to the legend of the
## visual variable `col` namely 'title' to 'col.legend = tm_legend(<HERE>)'
すごくおおざっぱにいうと2、Rのラスターデータは行列の各セルに緯度経度情報が紐づけされたものなので、各セルの値を通常の行列データのように呼び出すことができる。
# call data entry in cell row 1, column 12
rs_air[1, 12]## CHELSA_bio1_1981-2010_V.2.1
## 1 13.95このセルでは、13.95という気温の値が格納されているようだ。
ベクターレイヤと組み合わせる
この手のラスターデータに施す処理として、ベクターファイルと重ね合わせてデータを集計することがよくある。これらはsf、terra、exactextractrなどと組み合わせることで簡単にできる。exactextractrは必須というわけではないが、いろいろ便利な機能が備わっているのでおすすめ。
まず、前回のポストでも使用したNCのポリゴンデータを読み込む。これはNCのCountyという呼ばれる行政区のポリゴンをまとめたデータ。このデータはNAD27 というCRSが使われている。ラスターのCRSにそろえるため、terra::crs()でラスターデータのCRSを抽出し、st_transform()でポリゴンCRSをラスターCRSに合わせるよう変換する。
# read county shape file for NC (example data in `sf`)
# sf::st_read() reads a shape file
# sf::st_transform() transforms CRS (in this case, to WGS 84)
sf_nc <- system.file("shape/nc.shp", package="sf") %>%
st_read() %>%
st_transform(crs = crs(rs_air)) %>%
dplyr::select(NAME) # remove other than NAME column## Reading layer `nc' from data source
## `C:\Users\akira\OneDrive - UNCG\Documents\R\win-library\4.0\sf\shape\nc.shp'
## using driver `ESRI Shapefile'
## Simple feature collection with 100 features and 14 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: -84.32385 ymin: 33.88199 xmax: -75.45698 ymax: 36.58965
## Geodetic CRS: NAD27print(sf_nc)## Simple feature collection with 100 features and 1 field
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: -84.32377 ymin: 33.88212 xmax: -75.45662 ymax: 36.58973
## Geodetic CRS: WGS 84
## First 10 features:
## NAME geometry
## 1 Ashe MULTIPOLYGON (((-81.47258 3...
## 2 Alleghany MULTIPOLYGON (((-81.23971 3...
## 3 Surry MULTIPOLYGON (((-80.45614 3...
## 4 Currituck MULTIPOLYGON (((-76.00863 3...
## 5 Northampton MULTIPOLYGON (((-77.21736 3...
## 6 Hertford MULTIPOLYGON (((-76.74474 3...
## 7 Camden MULTIPOLYGON (((-76.00863 3...
## 8 Gates MULTIPOLYGON (((-76.56218 3...
## 9 Warren MULTIPOLYGON (((-78.30849 3...
## 10 Stokes MULTIPOLYGON (((-80.02545 3...このポリゴンデータとラスターデータを重ね合わせて図示してみる。
tm_shape(rs_air) +
tm_raster(title = "Temperature") +
tm_shape(sf_nc) +
tm_polygons(alpha = 0.5) # `alpha` specifies transparency## ## ── tmap v3 code detected ───────────────────────────────────────────────────────## [v3->v4] `tm_raster()`: migrate the argument(s) related to the legend of the
## visual variable `col` namely 'title' to 'col.legend = tm_legend(<HERE>)'
## [v3->v4] `tm_polygons()`: use `fill_alpha` instead of `alpha`.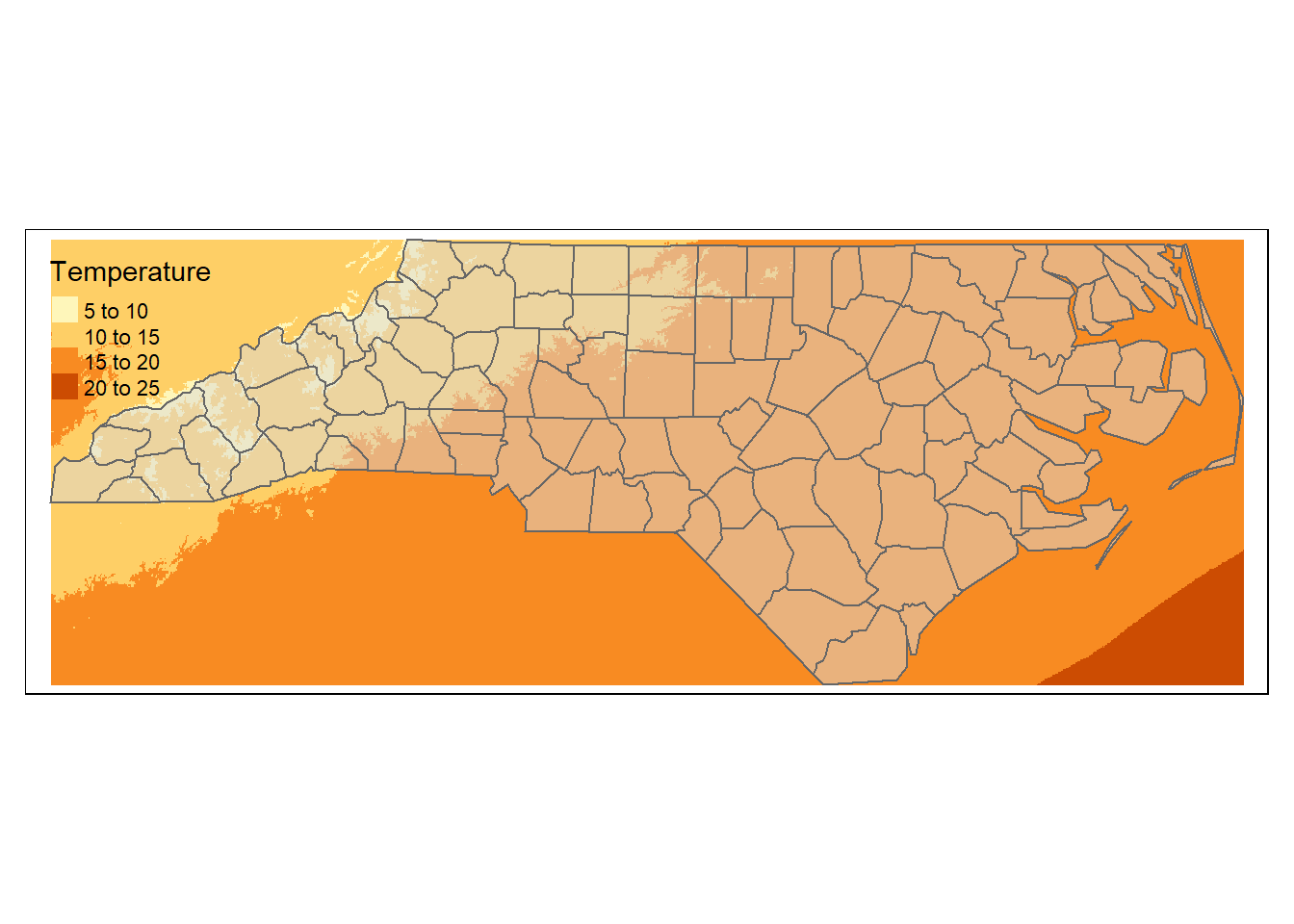
crop() :必要な部分のみ切り抜く
ラスターの必要な部分のみを切り抜くにはterra::crop()が使える。例として、NCの一つのCountyポリゴンでラスターデータを切り抜いてみる。
## pick the first element
poly <- sf_nc[1, ]
## `rs_air` cropped by `poly`
rs_air_cr <- crop(x = rs_air, y = poly)
print(rs_air_cr)## class : SpatRaster
## dimensions : 43, 60, 1 (nrow, ncol, nlyr)
## resolution : 0.008333333, 0.008333333 (x, y)
## extent : -81.74181, -81.24181, 36.23319, 36.59153 (xmin, xmax, ymin, ymax)
## coord. ref. : lon/lat WGS 84 (EPSG:4326)
## source(s) : memory
## varname : airtemp_nc
## name : CHELSA_bio1_1981-2010_V.2.1
## min value : 6.95
## max value : 14.05## visualize
tm_shape(rs_air_cr) +
tm_raster(title = "Temperature") +
tm_shape(poly) +
tm_polygons(alpha = 0.5)## ## ── tmap v3 code detected ───────────────────────────────────────────────────────## [v3->v4] `tm_raster()`: migrate the argument(s) related to the legend of the
## visual variable `col` namely 'title' to 'col.legend = tm_legend(<HERE>)'
## [v3->v4] `tm_polygons()`: use `fill_alpha` instead of `alpha`.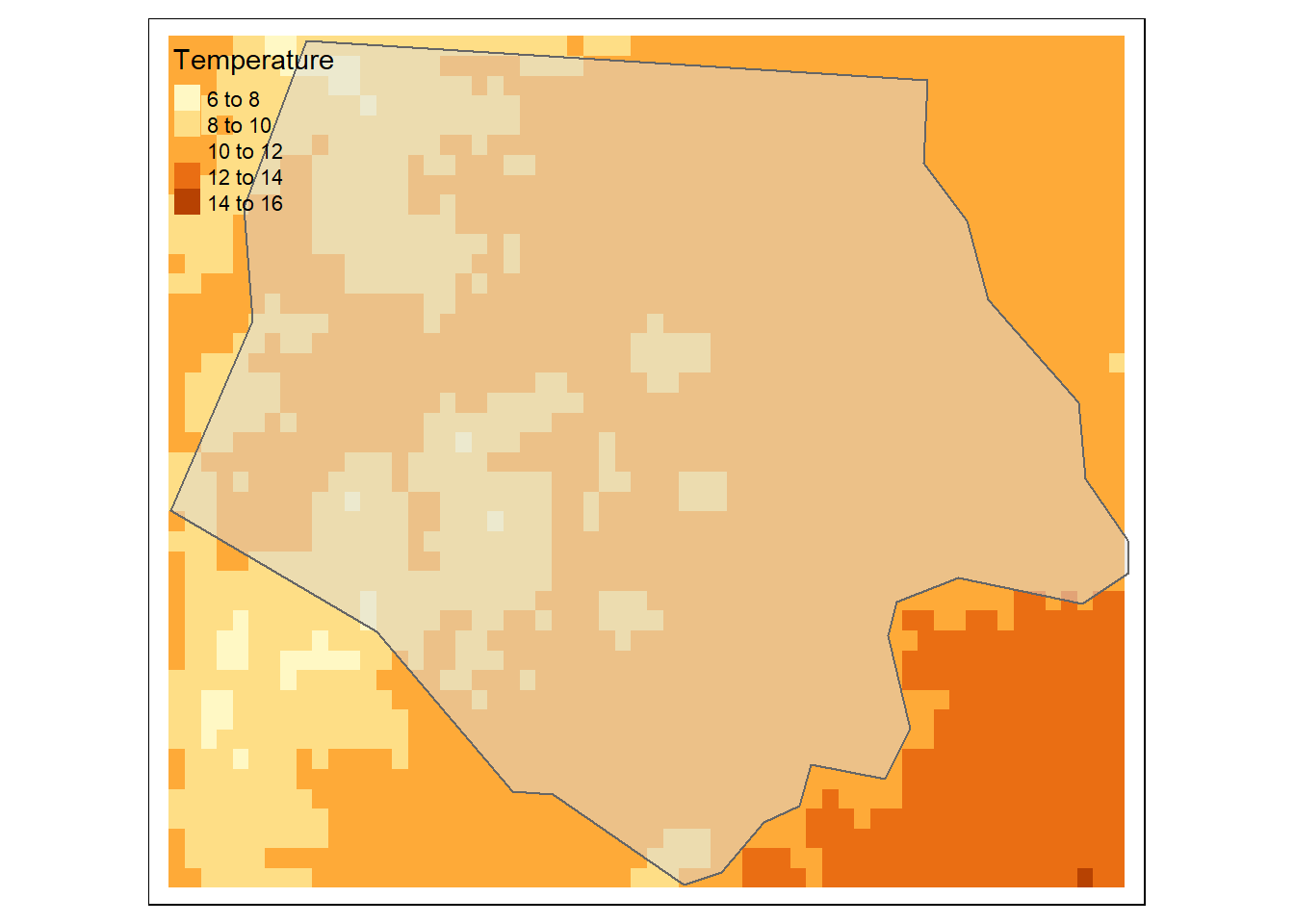
exact_extract() :ポリゴンごとに値を集計
ポリゴンごとにラスター値を集計(平均など)をとりたいこともある。exactextractr::exact_extract() が便利で、しかも鬼のように速い。また、ポリゴンが不完全にラスターセルと重なっている場合、重なりの割合をとったうえで重み付き平均を返してくれる。
df_temp <- exact_extract(x = rs_air,
y = sf_nc,
weights = "area",
fun = "weighted_mean",
append_cols = TRUE) %>%
as_tibble() %>%
rename(temperature = weighted_mean)## | | | 0% | |= | 1% | |= | 2% | |== | 3% | |=== | 4% | |==== | 5% | |==== | 6% | |===== | 7% | |====== | 8% | |====== | 9% | |======= | 10% | |======== | 11% | |======== | 12% | |========= | 13% | |========== | 14% | |========== | 15% | |=========== | 16% | |============ | 17% | |============= | 18% | |============= | 19% | |============== | 20% | |=============== | 21% | |=============== | 22% | |================ | 23% | |================= | 24% | |================== | 25% | |================== | 26% | |=================== | 27% | |==================== | 28% | |==================== | 29% | |===================== | 30% | |====================== | 31% | |====================== | 32% | |======================= | 33% | |======================== | 34% | |======================== | 35% | |========================= | 36% | |========================== | 37% | |=========================== | 38% | |=========================== | 39% | |============================ | 40% | |============================= | 41% | |============================= | 42% | |============================== | 43% | |=============================== | 44% | |================================ | 45% | |================================ | 46% | |================================= | 47% | |================================== | 48% | |================================== | 49% | |=================================== | 50% | |==================================== | 51% | |==================================== | 52% | |===================================== | 53% | |====================================== | 54% | |====================================== | 55% | |======================================= | 56% | |======================================== | 57% | |========================================= | 58% | |========================================= | 59% | |========================================== | 60% | |=========================================== | 61% | |=========================================== | 62% | |============================================ | 63% | |============================================= | 64% | |============================================== | 65% | |============================================== | 66% | |=============================================== | 67% | |================================================ | 68% | |================================================ | 69% | |================================================= | 70% | |================================================== | 71% | |================================================== | 72% | |=================================================== | 73% | |==================================================== | 74% | |==================================================== | 75% | |===================================================== | 76% | |====================================================== | 77% | |======================================================= | 78% | |======================================================= | 79% | |======================================================== | 80% | |========================================================= | 81% | |========================================================= | 82% | |========================================================== | 83% | |=========================================================== | 84% | |============================================================ | 85% | |============================================================ | 86% | |============================================================= | 87% | |============================================================== | 88% | |============================================================== | 89% | |=============================================================== | 90% | |================================================================ | 91% | |================================================================ | 92% | |================================================================= | 93% | |================================================================== | 94% | |================================================================== | 95% | |=================================================================== | 96% | |==================================================================== | 97% | |===================================================================== | 98% | |===================================================================== | 99% | |======================================================================| 100%print(df_temp)## # A tibble: 100 × 2
## NAME temperature
## <chr> <dbl>
## 1 Ashe 10.5
## 2 Alleghany 11.1
## 3 Surry 13.9
## 4 Currituck 15.8
## 5 Northampton 15.8
## 6 Hertford 15.8
## 7 Camden 15.8
## 8 Gates 15.8
## 9 Warren 15.5
## 10 Stokes 14.4
## # ℹ 90 more rowsxにラスター、yにベクター(ポリゴン)を指定する。funの部分をweighted_meanにすることで、weightsで指定した重み情報を元に重み付き平均をとってくれる。今回は、重みを面積(”area”)として計算している3。平均以外にもいろんな要約関数が用意されているし、自分で関数を定義することもできる。
ただし、最低限の知識として、緯度経度座標系、投影座標系の知識くらいはないと、まったく意味のないとんちんかんな計算をする可能性があるので、その辺は自学の必要あり(致命的な計算ミスにつながる可能性極大)。
この集計結果を、もとのポリゴンデータにくっつけて図示する。
sf_nc <- sf_nc %>%
left_join(df_temp)## Joining with `by = join_by(NAME)`print(sf_nc)## Simple feature collection with 100 features and 2 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: -84.32377 ymin: 33.88212 xmax: -75.45662 ymax: 36.58973
## Geodetic CRS: WGS 84
## First 10 features:
## NAME temperature geometry
## 1 Ashe 10.45288 MULTIPOLYGON (((-81.47258 3...
## 2 Alleghany 11.12001 MULTIPOLYGON (((-81.23971 3...
## 3 Surry 13.88488 MULTIPOLYGON (((-80.45614 3...
## 4 Currituck 15.82795 MULTIPOLYGON (((-76.00863 3...
## 5 Northampton 15.80508 MULTIPOLYGON (((-77.21736 3...
## 6 Hertford 15.84248 MULTIPOLYGON (((-76.74474 3...
## 7 Camden 15.82066 MULTIPOLYGON (((-76.00863 3...
## 8 Gates 15.76584 MULTIPOLYGON (((-76.56218 3...
## 9 Warren 15.48028 MULTIPOLYGON (((-78.30849 3...
## 10 Stokes 14.41932 MULTIPOLYGON (((-80.02545 3...## col = "temperature"
## - polygons colored by the values in "temperature" column
tm_shape(sf_nc) +
tm_polygons(col = "temperature")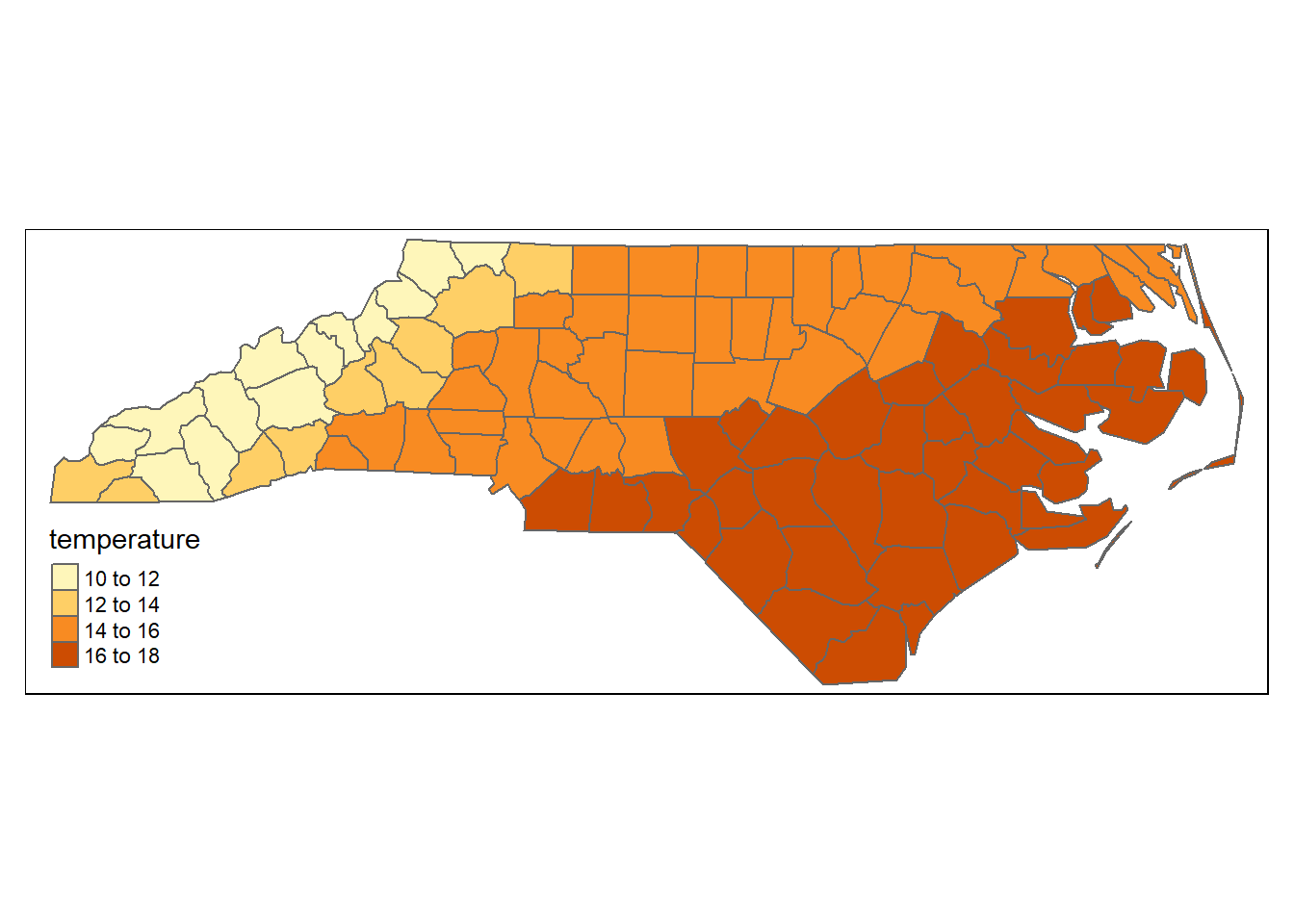
最後に
これらのパッケージの使い方は、パッケージのウェブページや、R GIS系のウェブブックなどで自学できる。こちらのページでRGISを勉強できるウェブサイトが一覧になっているので、各自のニーズや好みに合わせて使い分けるといいと思われる。
Rmarkdownの使用上
here::here()で絶対パスを使っているが、通常は相対パスでOK。↩︎もちろん実際はもっと複雑だが、その辺は私の知識の範疇を超える。↩︎
注意点として、インプットデータに地理座標系(今回のようなWGS84など)を使っている場合、
weights="area"としておかないと、変な平均値を計算してしまう。というのも、緯度経度座標系は歪んでいるので、赤道から離れるほど一つのセルの面積が小さくなる。weights="area"とすることで、この関数は各セルの面積に対応する値を自動計算し、その値をもとに重み付き平均をとってくれる。投影座標系の場合、weightsを指定せずにfun=”mean”としても同じ結果が返ってくる。このあたりは煩雑なので、座標系の理解を深めたのち、exact_extract()関数のHelpを熟読したほうがよい。↩︎